7 MIN READ
SIDE PROJECT
AI RECEPTIONIST
VOICE AGENTS · 2025
BUILT END-TO-END
Reported a leak under the kitchen sink last week. Prefers afternoons.
A missed call is a lost customer, and most businesses can’t staff a front desk around the clock. I bet voice agents had just gotten good enough to answer for real, so I built an AI receptionist any business can point a phone number at. It answers in their voice, remembers every caller, and replies in about 300ms, fast enough to feel like a conversation. Built end-to-end, multi-tenant from day one.
Small businesses lose real money to the phone. After hours, during a rush, on a holiday, the call goes unanswered and the customer calls the next place. Hiring a 24/7 front desk isn’t realistic for most of them. For years the obvious fix, an automated one, was worse than nothing: it sounded like a machine and everyone hung up.
What changed is speed. Voice models got good, and fast inference on Groq’s LPU got the round-trip low enough that a caller doesn’t notice the gap. There’s a line where it stops sounding like software. Under it, people talk to it like a person. Over it, they give up. I bet we’d crossed it, so I built a receptionist to find out.
Point a phone number at it and it answers, then gets smarter about each caller over time. Here are the surfaces that run it, and the shape underneath.
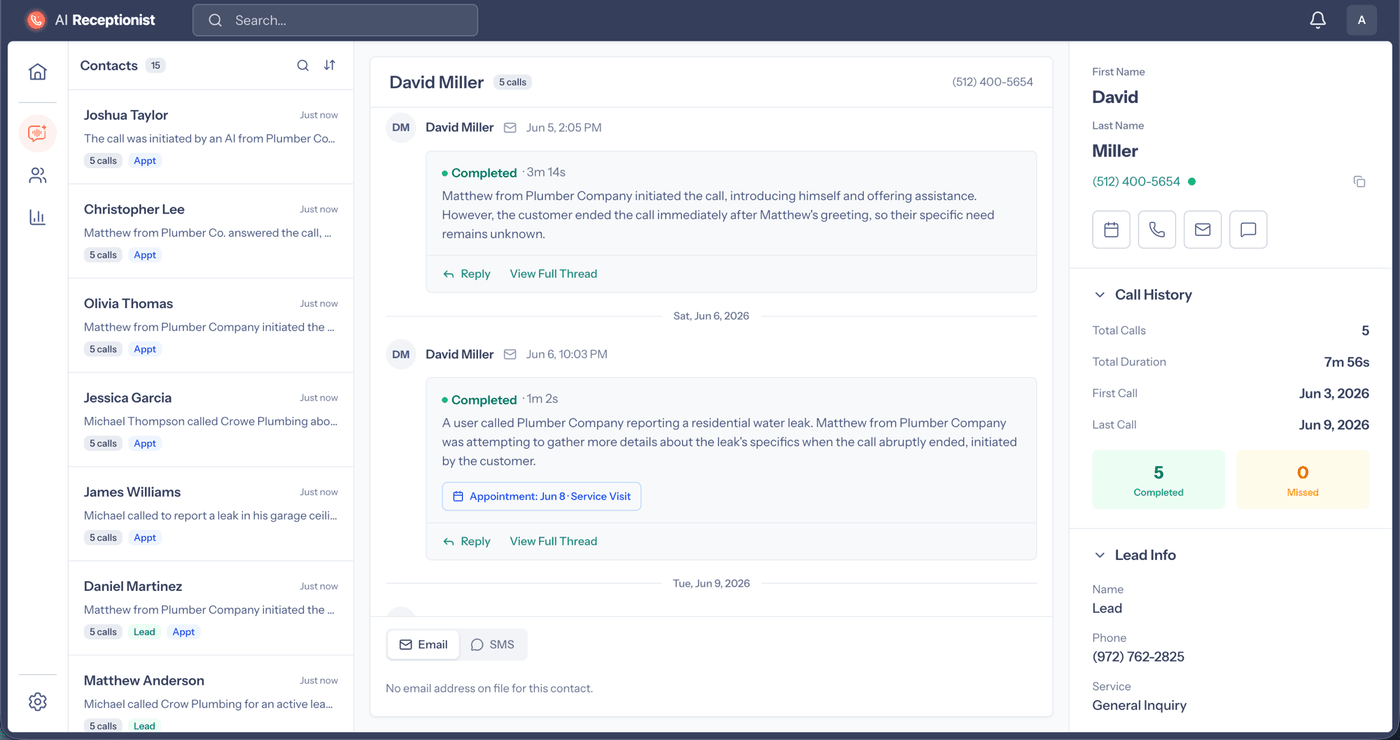
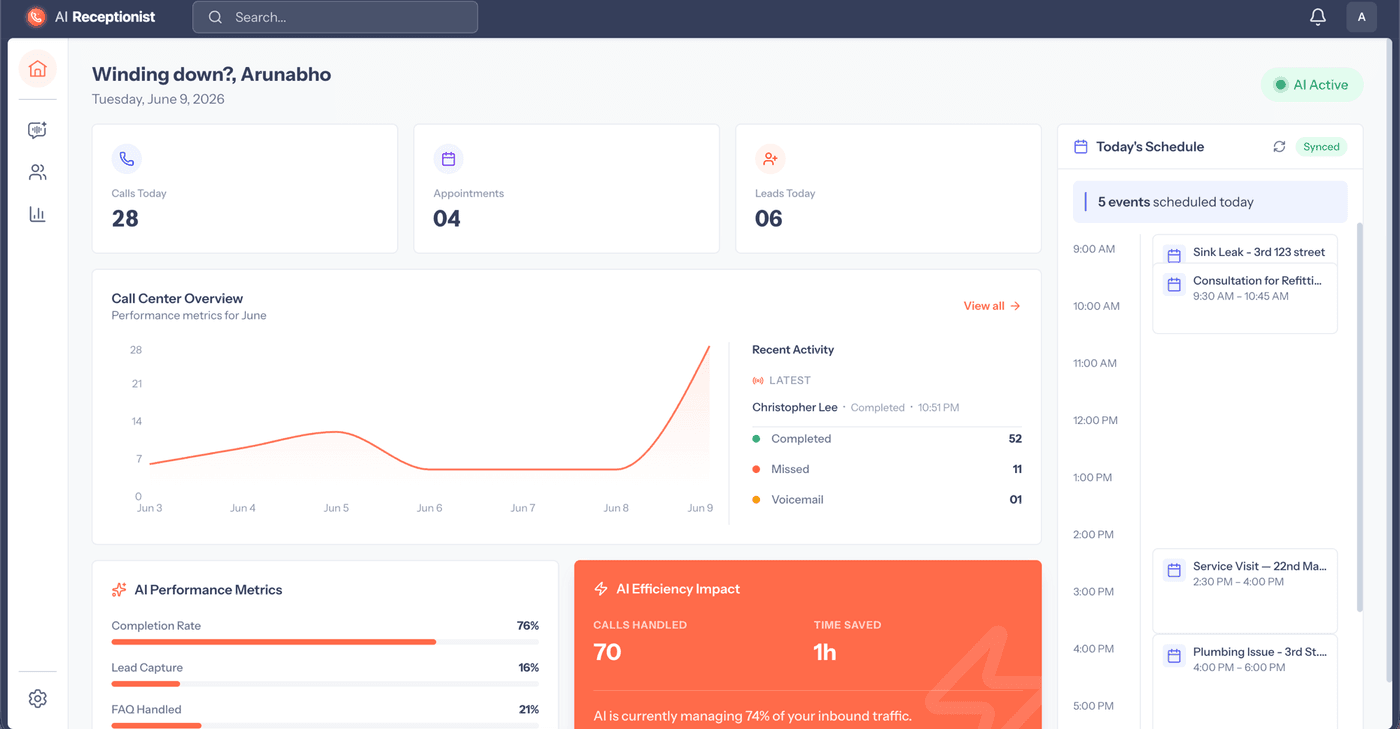
The home a business logs into - calls, appointments and leads today, the call-volume trend, and the day’s schedule down the side.
The headline an owner actually checks: AI Active, and how much of the phone the agent is quietly handling.
It answers in the business’s voice, and a per-caller memory plus a knowledge graph mean it remembers who you are and what you asked last time - so repeat callers don’t start from zero.
Every caller gets a thread: each call summarised, appointments captured inline, full history at a glance.
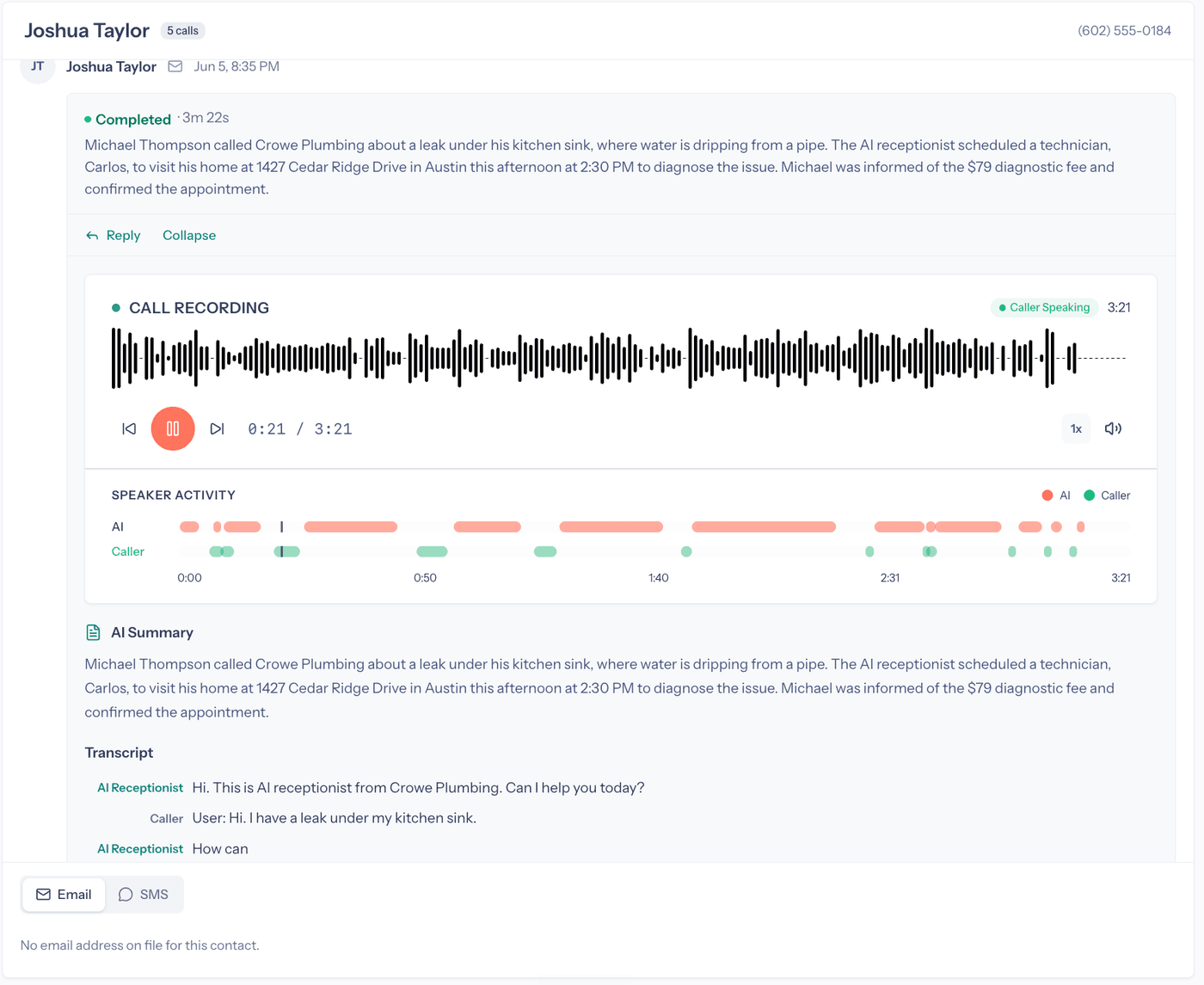
The recording, an AI-vs-caller speaker timeline, an auto-summary, and the verbatim transcript - so a business can check exactly what was said, and the agent can hand off cleanly when it should.
Calls route straight to the agent. A per-business config carries the hours, the services, and when to escalate to a human, so it behaves like their front desk.
It’s a multi-tenant service from the start: one system, many front desks. Onboarding a new business takes a number and a config. No new stack.
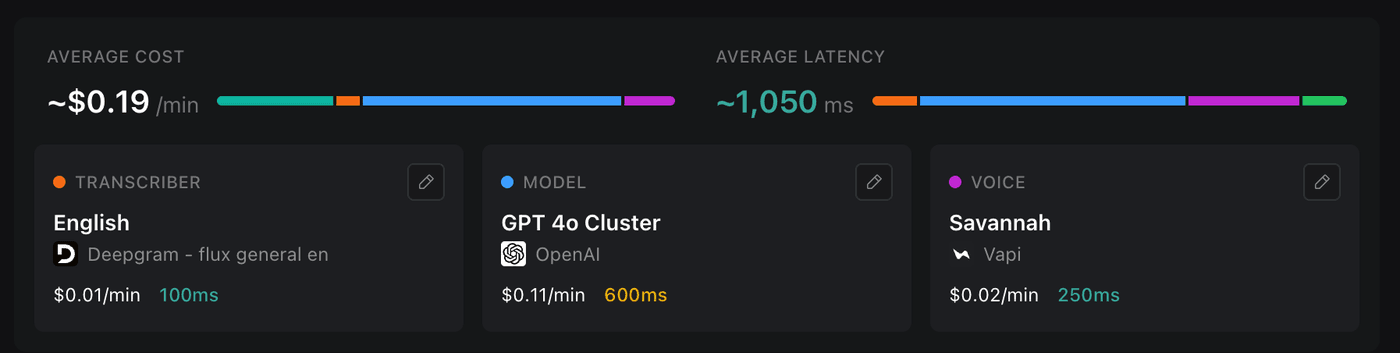
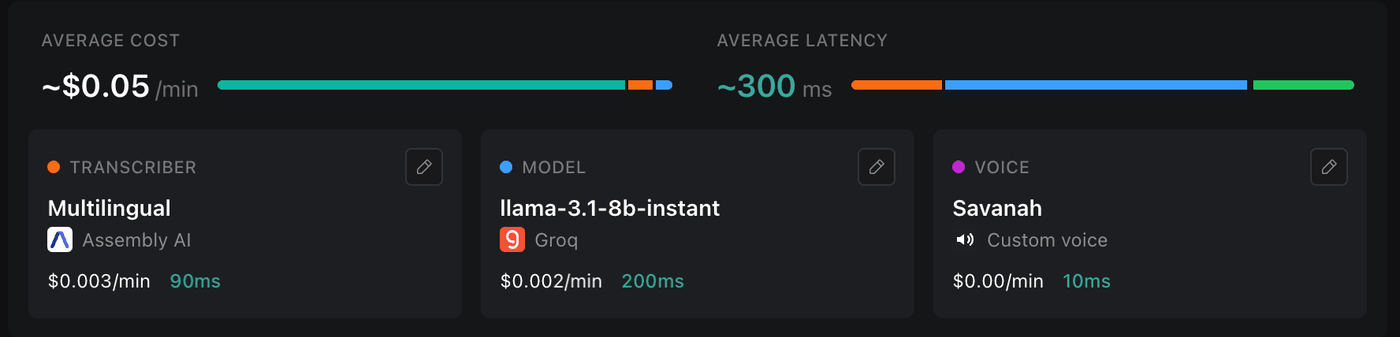
Everything else is downstream of one number. How long the caller waits before they hear a reply. At ~1,050ms it feels broken. People talk over it, repeat themselves, and hang up. Under ~300ms it feels alive. So the work wasn’t the conversation logic. It was tuning the whole stack until the gap disappeared: the transcriber, an open model on Groq’s LPU, a custom voice, the memory lookups. The same swap cut cost to a quarter, from ~$0.19 to ~$0.05 a minute, which is what makes running it for many businesses viable.
The other half of “feels real” is the same bar I hold on every AI product: it’s not allowed to be confidently wrong. A receptionist that invents your hours is worse than one that didn’t pick up. So it knows when to say it doesn’t know, and when to hand the call to a person.
Building it end to end meant the product calls were mine: the script and the escalation paths (when the agent should stop talking and get a human), the “never confidently wrong” bar, and the multi-tenant model that lets one system be many businesses’ front desk. Same instinct as Otto. In anything conversational and critical, the job is owning what the model is allowed to say, and how it behaves when it isn’t sure.
It’s a bet, and it’s still early. But the core question it answers, can a business never miss a call without hiring for it, is one a lot of people have.